
La identificación de relaciones en los documentos forma parte de un proyecto sobre el grafo de conocimiento.
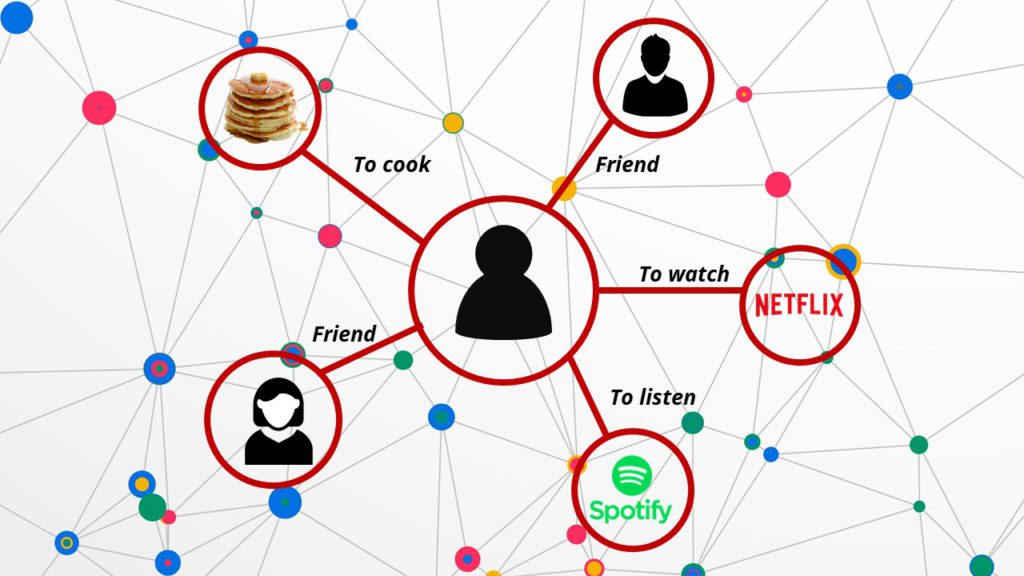
Un grafo de conocimiento es una forma de presentar gráficamente la relación semántica entre temas como personas, lugares, organizaciones, etc., lo que permite mostrar sintéticamente un cuerpo de conocimiento. Por ejemplo, la figura 1 presenta un gráfico de conocimiento de medios sociales, podemos encontrar alguna información sobre la persona en cuestión: amistad, sus aficiones y sus gustos.
El objetivo principal de este proyecto es aprender de forma semiautomática gráficos de conocimiento a partir de textos según el campo de especialidad. En efecto, los textos que utilizamos en este proyecto provienen de campos del sector público de gran altura que son: Estado civil y cementerio, Elecciones, Orden público, Urbanismo, Contabilidad y finanzas locales, Recursos humanos locales, Justicia y Sanidad. Estos textos editados por Berger-Levrault proceden de 172 libros y 12 838 artículos en línea de peritaje judicial y práctico.
Para empezar, un especialista en la materia analiza un documento o artículo repasando cada párrafo y elige anotarlo o no con uno o varios términos. Al final, hubo 52 476 anotaciones en los textos de los libros y 8 014 en los artículos, que pueden ser de varias palabras o de un solo término.
A partir de esos textos queremos obtener varios gráficos de conocimiento en función del dominio como en la figura siguiente:
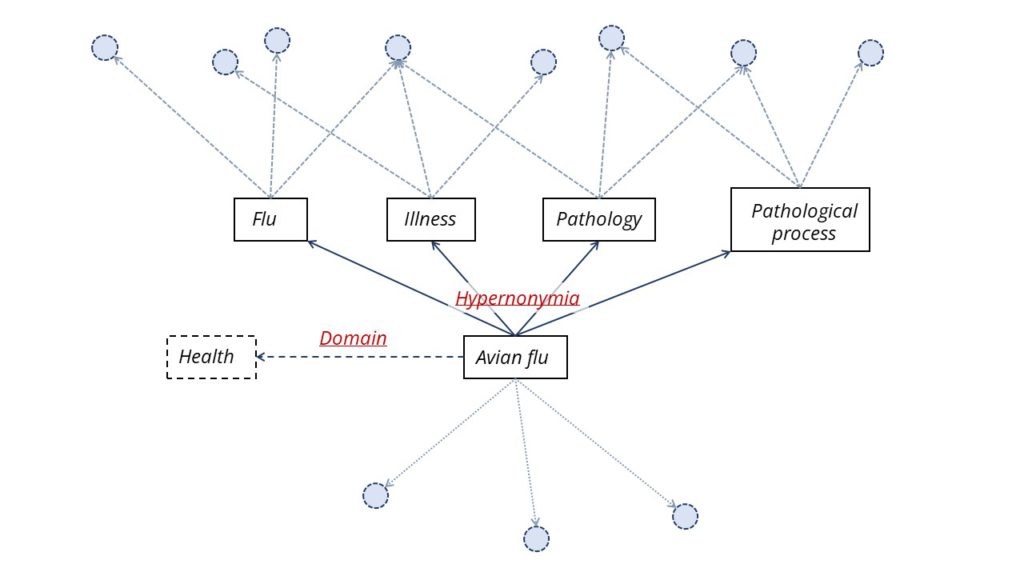
Al igual que en nuestro gráfico de redes sociales (figura 1), podemos encontrar la conexión entre las palabras de la especialidad. Eso es lo que queremos hacer. A partir de todas las anotaciones, queremos identificar la relación semántica para destacarla en nuestro grafo de conocimiento.
Explicación del proceso
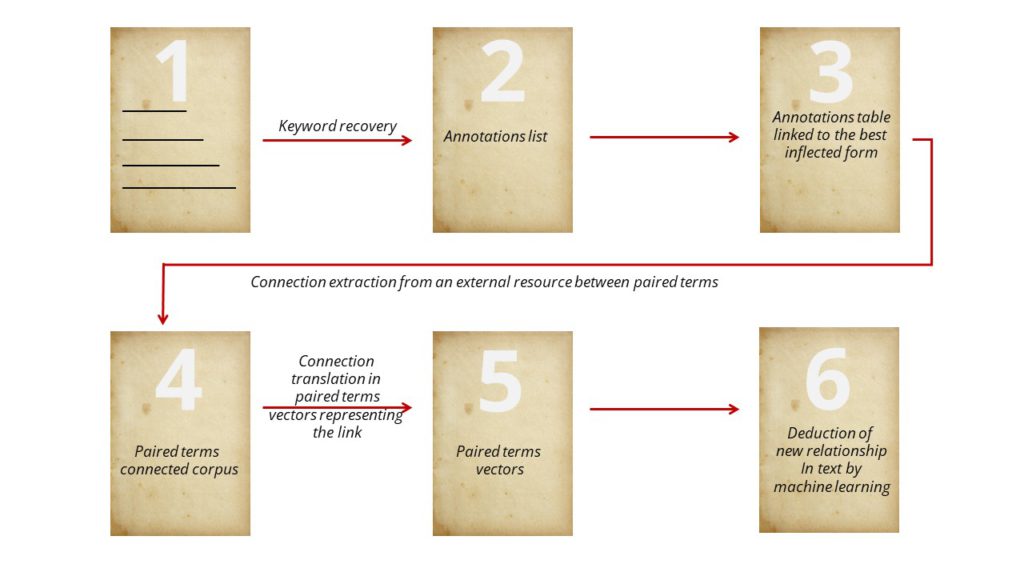
El primer paso es recuperar todas las anotaciones de los expertos en los textos (1). Estas anotaciones son accionado manualmente y los expertos no tienen un léxico referencial, así que pueden no utilizar el mismo término (2). Las palabras clave se describen con varias formas flexionadas y, a veces, con información adicional irrelevante como el determinante ("a", "el", por ejemplo). Así, procesamos todas las formas flexionadas para obtener una lista única de palabras clave (3).
Con estas palabras clave únicas como base, vamos a extraer de los recursos externos las conexiones semánticas. Por el momento, nos centramos en cuatro escenarios: la antonimia, términos con sentido opuesto; la sinonimia, términos diferentes con el mismo significado; la hipernonimia, que representa términos que pueden asociarse a los genéricos de un objetivo determinado, por ejemplo, "gripe aviar" tiene por término genérico "gripe", "enfermedad", "patología" y la hiponimia que asocia los términos a un objetivo específico determinado. Por ejemplo, "compromiso" tiene por término específico "boda", "compromiso a largo plazo", "compromiso social"...
Con el aprendizaje profundo, estamos construyendo vectores de términos contextuales de nuestros textos para deducir los términos pares que presentan una conexión determinada (antonimia, sinonimia, hipernimia e hiponimia) con operaciones aritméticas sencillas. Estos vectores (5) constituyen un juego de entrenamiento para la relación de aprendizaje automático. A partir de esas palabras emparejadas podemos deducir nuevas conexiones entre las palabras del texto que aún no se conocen.
La identificación de las conexiones es un paso crucial en la automatización de la construcción del grafo de conocimiento (también llamado base ontológica) multidominio. Berger-Levrault desarrolla y mantiene software de gran tamaño con compromiso con el usuario final, por lo que la empresa quiere mejorar su rendimiento en la representación del conocimiento de su base de edición a través de recursos ontológicos y mejorar el rendimiento de algunos productos utilizando esos conocimientos.
Perspectivas de futuro
Nuestra era está cada vez más influenciada por el predominio del volumen de big data. Estos datos generalmente esconden una gran inteligencia humana. Estos conocimientos permitirían a nuestros sistemas de información ser más eficaces en el tratamiento e interpretación de datos estructurados o no estructurados.
Por ejemplo, el proceso de búsqueda de documentos relevantes o la agrupación de documentos para deducir la temática no siempre son fáciles, especialmente cuando los documentos provienen de un sector específico. Del mismo modo, la generación automática de textos para enseñar a un chatbot o a un voicebot a responder preguntas se encuentra con la misma dificultad: falta una representación precisa del conocimiento de cada área de especialidad potencial que podría utilizarse. Por último, la mayoría de los sistemas de búsqueda y extracción de información se basan en una o varias bases de conocimiento externas, pero tienen dificultades para desarrollar y mantener recursos específicos en cada dominio.
Para obtener buenos resultados en la identificación de conexiones, necesitamos un gran número de datos, como los que tenemos con 172 libros con 52 476 anotaciones y 12 838 artículos con 8 014 anotaciones. Aunque las metodologías de aprendizaje automático pueden tener dificultades. En efecto, algunos ejemplos pueden estar débilmente representados en los textos. ¿Cómo podemos asegurarnos de que nuestro modelo capte todas las conexiones interesantes en ellos? Estamos considerando establecer otros métodos para identificar las relaciones poco representadas en los textos con metodologías simbólicas. Queremos detectarlos encontrando patrones en los textos enlazados. Por ejemplo, en la frase "el gato es un tipo de felino"podemos identificar el patrón "es una especie de". Permite relacionar "gato" y "felino" como el segundo genérico del primero. Así que queremos adaptar este tipo de patrón a nuestro corpus.



